
Je profite de deux articles que je viens de lire (GNU/Linux Magazine n°198 et 201) sur PostgreSQL et de quelques post pêchés sur le web pour vous faire une petite synthèse des avancées de PostgreSQL depuis la version 9.6 (on parlera un peu des autres quand même).
Dans ma vielle techno, il y a une page réservée à PostgreSQL. Elle évolue avec les versions et selon mes recherches et travaux.
Bon, je ne vous présente pas PostgreSQL, il s’agit d’un SGBDR de type objet. C’est probablement la meilleure base polyvalente de données Open Source aujourd’hui. Après, je ne parle pas de BigData et de NoSQL. C’est une sorte de concurrent de DB2, d’Oracle, de Microsoft SQL Server et de MariaDB… Mais en réalité, ça dépend fortement des besoins. Bon, ça donne quoi PostgreSQL aujourd’hui ? Je dois vous avouer que je l’ai utilisé intensément il y a quelques années (sans devenir une pointure non plus… mais dans le cadre de développements d’application) et je n’ai pas trop suivi les évolutions. Les voici…
Parallélisme / Multi-CPU
La principale avancée qu’on attendait depuis plusieurs années est le parallélisme, c’est à dire, la possibilité d’utiliser massivement (et intelligemment) les multiples processeurs d’une machine. Bon, quand on a un serveur avec 4 processeurs, c’est pas forcément flagrant, mais si on dispose d’une centaine de processeurs, ça devient carrément impératif. Pourquoi cela a t-il mis si longtemps ? Il faut savoir qu’à la base PostgreSQL est un système multi-processus et non multi-threads. Je vous rappelle la différence: A la différence des processus, les threads partage le même espace mémoire protégé, les mêmes ressources et le même espace mémoire. De fait, si on a plusieurs processus, il faut établir des zones spécifiques de mémoire partagée, c’est pas évident. En même temps, du multi-thread, c’est dangereux car si un thread plante ou fait une mauvaise manip en mémoire, les autres trinquent aussi. Bref, c’est plus facile de faire du multi-processus que du multi-threads car c’est moins dangereux.
PostgreSQL utilise donc plusieurs processus, pour l’écriture en tâche de fond, pour la maintenance, la réplication, etc. Mais voilà, si on a un ordinateur avec plusieurs CPU, un seul sera utilisé pour votre requête. Si la base est utilisée par de nombreux utilisateurs, ce n’est pas un soucis, la charge se réparti. Mais c’est quand même dommage de ne pas pouvoir exécuter une même requête sur plusieurs processeurs. C’est chose faite, en tous cas, c’est en très bonne voie, avec la version 9.6.
Pour faire cela, il y avait 2 possibilités: soit opter pour du multi-threads avec les implications dont nous avons déjà parlé, soit permettre aux processus de demander de l’aide d’autres processus. On les appelera les « workers » – oui, c’est bien la seconde solution qui a été retenue. En version 9.6, seules les requêtes en lecture pourront être parallélisées (sauf les tables temporaires). On peut étudier la façon dont les requêtes sont parallélisées en visualisant le Query Plan au travers de la commande Explain. Le niveau de parallélisation est indiqué par deux lignes: workers planned et workers launched:
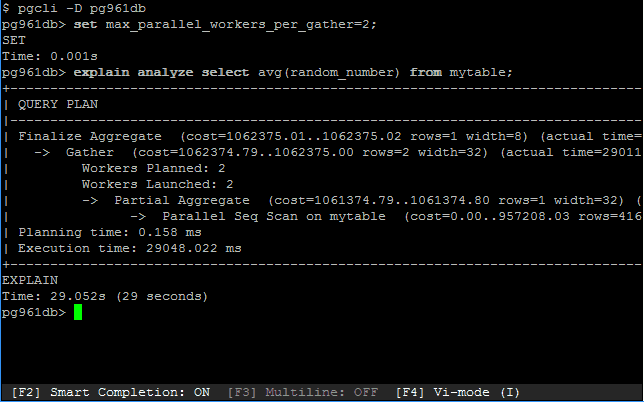
Je vous passe le fait qu’il est possible de paramétrer cela, voir même de spécifier par table le nombre de workers suggérés. Mais le moteur s’en charge très bien lui-même et estime quelques fois qu’une parallélisation est coûteuse et inutile. Bref, la parallélisation apporte, vous l’aurez compris, un gain de performance plus ou moins important selon le serveur.
SQL/MED
La version 8.3 a vu la mise en place d’une infrastructure SQL/MED ( Management of External Data). C’est une extension à SQL définie en 2003 offrant moyen à un SGBDR d’accéder à des données qu’il ne gère pas – à des tables externes par exemple. Imaginez que vous développiez une application pour la gestion de votre entreprise: il vous faut taper dans des données de ventes sous Oracle, des données du site web sous PosgreSQL et d’autres dans une base Informix par exemple .Grâce à un connecteur, Foreign Data Wrapper, il vous est possible d’interroger votre base PostgreSQL concernant des données qui sont ailleurs… permettant ainsi de faire des jointures et tout un tas d’autres trucs. Et pourquoi pas avec des bases NoSQL également.
Les tables externes sont apparues avec la version 9.1, mais elles n’étaient qu’en lecture seule. La version 9.3 a vu arriver la possibilité d’écrire dans ces tables. Enfin, la version 9.5 a permis la création automatique des tables d’une source distante. Mais c’est avec la 9.6 qu’ont été mises en place de nombreuses améliorations, notamment au niveau des jointures. Quand cela est possible, une jointure de deux tables externes est réalisée par le SGBD externe avant d’envoyer le résultat. En 9.5, ce n’était pas le cas, la jointure était réalisée en locale, en important en quelques sortes les deux extraits de table… d’où un gain de performance important aujourd’hui. De même, l’écriture dans des tables externes, les updates, les delete… tout cela est réalisé à distance. Bon, bien sûr, tout dépend du Wrapper ! Pour Oracle et PostgreSQL, ça fonctionne parfaitement. Mais pour les autres, ça va dépendre des développeurs de ces mêmes wrappers.
Réplication
La réplication, c’est le fait de pouvoir utiliser plusieurs bases des données synchronisées entre elles… bon, je n’ai pas une bonne définition en tête, alors voici un exemple: vous avez une base de données de clients et votre commercial part avec son portable dans une zone non-couverte et ne peut donc pas se connecter à distance. Il va utiliser une base de données locale. Cette base sera à jour si un mécanisme de réplication a permis de synchroniser les différentes tables avant qu’il ne parte en tournée. On parlera souvent d’une base maître (ou parente) et de bases esclaves (ou enfants) – bien qu’il existe des mécanismes plus complexes où il n’y a pas de notion de priorité aussi simpliste.
On parle de réplication bi-directionnelle si on veut que les bases enfants puissent également envoyer des modifications à la base parente, avec tous les conflits que cela peut produire – d’où une gestion de conflits à mettre en place, avec des priorités à régler. On parle de réplication synchrone quand les bases sont connectées et que les modifications sont immédiatement prises en compte, ou asynchrone quand il peut s’écouler un délai, comme dans le cas de notre commercial. On parle aussi de réplication journalée.
J’avais bossé sur le cas d’une réplication bi-directionnelle et asynchrone il y a quelques années, alors qu’aucun mécanisme de réplication n’était intégré au sein de PostgreSQL. J’avais utilisé pour cela une librairie écrite en Ruby dont j’ai oublié le nom (rubyrep probablement). Mais le cas était assez compliqué et la solution avec un fichier de réplicats (comme sous Windev avec Hyperfile) n’était pas vraiment top. Mais ça fonctionnait… lentement, mais sûrement.
La solution interne de réplication de PostgreSQL est aujourd’hui une solution asymétrique: un serveur maître (on dit « primaire« , c’est plus pro) permet l’écriture, mais les secondaires (les esclaves… les enfants, vous voyez) ne permettent que la lecture – pas de conflit ainsi. C’est une solution asynchrone, bien qu’il soit possible de la rendre synchrone en le paramétrant. C’est au niveau des serveurs synchrones qu’il y a le plus d’optimisations avec la 9.6.
Divers
Ce qui me plait ien aussi avec la version 9.6, c’est la possibilité de rechercher des phrases (fulltext search) dans une base de données. Imaginez que vous indexiez des documents d’une GED. Vous exportez tous les docs dans une version TXT stockée dans une table. Et vous voulez faire un moteur de recherche type Apache Lucene. Désormais, vous pouvez lancer des requêtes en indiquant le texte à rechercher, mais aussi le nombre de mots entre 2 mots clés, etc. En effet, avant la 9.6, on pouvait chercher les documents contenant 2 mots clés ou plus, mais pas qui se suivent. Pour ce faire, il fallait utiliser des iLike et c’était coûteux en ressources. Aujourd’hui, non seulement on peut le faire, mais aussi indiquer le nombre max de mots intermédiaires (opérateur <-> ou <n> avec n le nombre de mots) – ce qui dans un document complet de plusieurs pages change bien la donne. Bon, pour la mise en pratique, suivez ce lien.
Voilà, il y a d’autres optimisations comme au niveau des VACUUM FREEZE, des CHECKPOINT, du GROUP BY … de la gestion du cache des écritures, de la sauvegarde PITR et même au niveau de l’administration, mais je vous laisse découvrir cette liste sur cette page, ce sera plus simple.
Ce que je retiens, c’est cette indication de la progression d’une commande qui commence à poindre du nez. Cela ne fonctionne que pour le VACUUM pour l’instant (et pas le full), mais c’est le début et y-a fort à parier que toutes les commandes finiront par en bénéficier. Imaginez que vous lanciez une longue requête et qu’en temps-réel vous pouvez savoir où ça en est ! Un peu comme quand on copie un fichier en quelques sortes. Même si l’information est plus ou moins heuristique, ce sera un bon indicateur pour aider à patienter – mais aussi pour savoir si on fait pas d’autres choses en même temps – le programme, pas vous… j’imagine que vous avez une main sur la souris et une autre sur la tassé de café 😉 Bref, plus de possibilités pour le développeur !
Une autre fonctionnalité intéressante c’est la possibilité d’obtenir plus de détails sur une session bloquée (dans la table pg_stat_activity).
Quid de la version 10 ?
Il semblerait qu’un véritable support pour le partitionnement de table sera implémenté ! Le partitionnement fait référence à la division d’une table volumineuse en plusieurs tables plus petites, appelées partitions. Cela permet d’améliorer la gestion, la performance des tables ou la disponibilité des données. Chaque partition se retrouve sur des serveurs ou des disques différents. Cela permet également d’obtenir une capacité de base de données supérieure à la taille maximum des disques durs ou d’effectuer des requêtes en parallèle sur plusieurs partitions. C’est la notion de sharding ou de distribution des données.
PostgreSQL offre déjà un support du partitionnement de tables, mais il s’agit d’un support basique à travers l’héritage de tables. Pas très pratique. Avec le partitionnement natif, tout sera réalisé en arrière-plan, il n’y aura pas besoin de gérer un tas de choses. Il suffira de déclarer comment une table doit être partitionnée, sans devoir implémenter les détails. Avec Oracle par exemple, la table partitionnée est vue par le développeur comme une unique table, mais comme plusieurs par le moteur Oracle.
Conclusion
Voilà, très intéressantes ces nouvelles fonctionnalités, et il reste encore beaucoup de choses à venir avec la version 10. On sent aussi avec le partitionnement la pression faite par le Big Data sur l’ensemble des SGBD. Aujourd’hui, tout est affaire de Big Data pour le stockage et de Deep Learning pour la compréhension des données… ne passez pas à coté, même si vous êtes dans le jeu vidéo !



0 commentaires