
Je vous avais déjà parlé d’Hadoop dans cet article sur « Limites des SGBDR pour le Big Data, NoSQL et NewSQL« . Hadoop est un framework libre et open source écrit en Java destiné à faciliter la création d’applications distribuées pour le stockage de données, permettant aux applications de travailler avec des milliers de nœuds et des pétaoctets de données ! Rien que ça… Et Spark ? C’est un peu la même chose… en mieux ? Oui et Non… je ne peux pas répondre sans vous présenter le tout. C’est pas si compliqué vous allez voir. Et cerise sur le gâteau, on va parler de Machine Learning également !
Apache Hadoop: le linux du Big Data ?
Pour la petite histoire, Tout a commencé en 2004, lorsque Google publie un article présentant son algorithme basé sur des opérations analytiques à grande échelle sur un grand cluster de serveurs, le MapReduce, ainsi que son système de fichier en cluster, le GoogleFS. Doug Cutting, qui travaille à cette époque sur le développement de Apache Lucene et rencontre des problèmes similaires à ceux de Google, décide alors de développer sa propre version des outils en version Open Source, qui deviendra le projet Hadoop.
Hadoop, c’est aussi un écosystème logiciel car il est la base de nombreux outils, parmis lesquels:
-
Hbase: SGBD non-relationnel, distribué, écrit en Java, et disposant d’un stockage structuré pour les grandes tables. Comme BigTable, HBase est une base de données orientée colonnes. Hive, c’est la version relationnelle ! On en reparle plus loin.
-
Mahout: implémentations d’algorithmes d’apprentissage automatique distribués. Nous en reparlerons dans la section Machine Learning.
-
Spark:Non, pas la messagerie 😉 C’est un peu la suite d’Hadoop… plus rapide que MapReduce. En 2014, Spark a gagné le Daytona GraySort Contest dont l’objectif est de trier 100 To de données le plus rapidement possible. Ce record était préalablement détenu par Hadoop. Pour ce faire, Spark a utilisé 206 machines obtenant un temps d’exécution final de 23 minutes alors que Hadoop avait lui utilisé 2100 machines pour un temps d’exécution final de 72 minutes. La puissance de Spark fut démontrée en étant 3 fois plus rapide et en utilisant approximativement 10 fois moins de machines.
Et c’est sans parler de Ambari, Avro, Cassandra, Chukwa, Pig, Tez et ZooKeeper.
Hadoop peut-être utilisé dans un cloud traditionnel. Par exemple, il est possible d’exécuter Hadoop sur Amazon Elastic Compute Cloud (EC2) et sur Amazon Simple Storage Service (S3). Ainsi que sur Microsoft Azure.
Apache Spark
Présenté comme je l’ai fait, on se dit que Spark est différent d’Hadoop et on se demande même pourquoi je ne parle pas uniquement de Spark vu les lamentables résultats d’Hadoop…
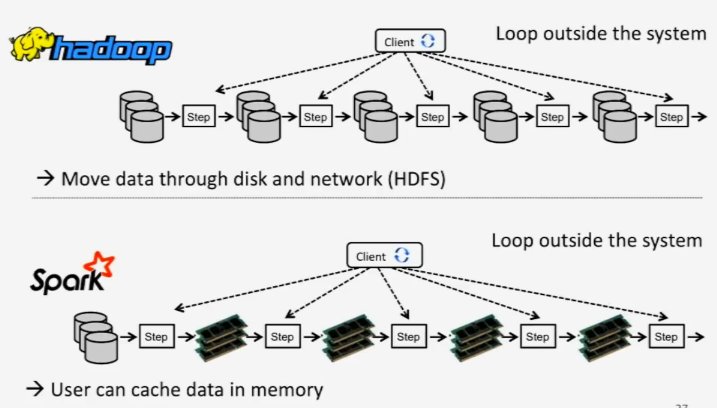
Hadoop, c’est un système de fichiers distribué HDFS (Hadoop Distributed File System), l’implémentation de Mapreduce, c’est un SGBD distribué (Hive, Hbase), et d’autres outils comme vu ci-dessus. Spark était un projet différent à l’origine, mais il est venu se greffer au projet progressivement. À l’origine, en 2009, son développement est une solution pour accélérer le traitement des systèmes Hadoop. Ce n’est qu’en 2013 qu’il rejoindra officiellement la fondation Apache.
Si les deux outils sont parfois considérés comme des concurrents, il est souvent admis qu’ils fonctionnent encore mieux quand ils sont ensemble. C’est là toute la complémentarité ! Tous deux sont des frameworks big data, mais Hadoop est essentiellement une infrastructure de données distribuées. Spark sait travailler avec des données distribuées. Mais il ne sait pas faire du stockage distribué. Il a donc besoin de s’appuyer sur un système de stockage distribué. Toutefois, il est possible d’utiliser Hadoop indépendamment de Spark et réciproquement. Dans ce cas, Spark devra quand même s’appuyer sur un autre système de fichiers, comme celui proposé par un cloud par exemple.
Voilà, il y a d’autres différences, mais vous connaissez les principales et surtout vous aurez de quoi de discuter durant les longues soirées mondaines entre développeurs… ah, ça n’existe pas ? Bon, les discussions coca/chips à l’heure de l’apéro, ou la pause café à coté de la machine ! Si, c’est bon de socialiser et de faire des pauses, je vous assure.
Vous allez comprendre pourquoi Spark m’intéresse le plus dans cette histoire. Mais avant cela, parlons des outils liés à Spark:
-
Spark SQL : permet d’exécuter des requêtes SQL qui peut être utilisé pour traiter n’importe quelles données, quel que soit leur format d’origine
-
Spark Streaming: offre à son utilisateur un traitement des données en flux.
-
Spark Graph X : permet de traiter les informations issues de graphes.
Mais surtout:
-
Spark MLlib: C’est une bibliothèque d’apprentissage automatique, apparue dans la version 1.2 de Spark, qui contient tous les algorithmes et utilitaires d’apprentissage classiques, comme la classification, la régression, le clustering, le filtrage collaboratif et la réduction de dimensions. Bien entendu, nous reviendrons sur cette librairie plusieurs fois sur ce blog 😉
Pour aller plus loin
J’en profite pour vous livrer quelques infos de mon flux de veille sur le sujet.
Pour Hadoop:
-
La FAQ Hadoop sur developpez est sympa aussi. Un article « Hadoop : la nouvelle infrastructure de gestion de données » présente de façon synthétique le fonctionne d’Hadoop.
-
Pour installer Hadoop, choisir sa distribution, etc. Xebia les spécialistes du Big Data et du Machine Learning vous ont concocté un article sur la question.
-
Je vous propose également un petit article qui parle des difficultés à déployer une telle solution en entreprise, car cela demande des compétences transversales rares et que les dirigeants ont souvent des attentes irréalistes.
-
Un article de Juvénal Chokogoue sur developpez parlant de « Le SQL dans Hadoop : HiveQL et Pig ». On y découvre l’infrastructure de Hive et l’écriture des requêtes HiveQL (Hive Query Language) qui est utilisé pour adresser des requêtes aux données stockées sur le HDFS sous une forme SQL. Et Pig, c’est la solution de Yahoo pour faire la même chose, ces derniers ayant estimé qu’une solution basée sur le SQL ne pouvait pas suffisamment couvrir la complexité de la programmation de certaines tâches MapReduce.
Pour Spark:
-
Un petit tuto pour apprendre à utiliser Spark dans le cadre d’une requête sur une grosse base. C’est très intéressant car on balance un gros CSV, la config est rapide et on voit comment manipuler les données, puis effectuer des requêtes. C’est une très bonne intro en français. Et on nous promet une seconde partie comment faire du machine learning avec l’API Spark MLlib ! Miam !
-
Spark est plus puissant et plus simple à utiliser que MapReduce, mais comment tester du code Spark ? La réponse dans cet article par Xébia. Et on revient sur la La programmation fonctionnelle ! (vous vous rappelez, on en a parlé avec Haskell que je trouvais inutile). Car oui, Spark fait usage de la programmation fonctionnelle. One ne peut pas tester un framework mais seulement les comportements fonctionnels.
-
Une bonne introduction à Spark Mllib par Xébia. On y apprend que les limites de Mahout étant rapidement atteintes lorsque l’on a affaire à de gros jeux de données à cause du coté itératif de la plupart des algorithmes de Machine Learning. 2 articles au final, l’un théorique et l’autre pratique. J’envisage de faire une vidéo prochainement sur le sujet, dites moi si cela vous intéresse. J’ai vu qu’ils avaient publié sur Developpez également avec du code source sur Github… à voir, cela semble redondant.
-
Une présentation de SparkR, la nouvelle API de Spark pour programmer en R (langage adapté aux stats)
Conclusion
Voilà, j’espère que cet article vous a donné envie d’aller plus loin dans la démarche d’apprendre et comprendre cet écosystème logiciel. En gros, pour résumer: Avec Spark/Hadoop, vous pouvez traiter de gros volumes de données de façon distribuée, sur des cloud traditionnels, tout en traitant ces dernières avec des outils de machine learning. Comme mes centres d’intérêt tourne autour de la 3D, du machine Learning et de la robotique, vous comprenez qu’on va vite en reparler…



0 commentaires