
Avez-vous déjà créé un robot ? C’est fun, on peut le doter d’un système de locomotion, de capteurs de proximité, d’une webcam… voir d’un bras articulé. On fait mumuse quelques semaines et puis on se dit au final… hey, je fais comment maintenant pour le rendre intelligent et lui confier certaines tâches ?

Quand on créé des robots en jeu vidéo, on peut utiliser des déclencheurs de proximité, on a des fonctions comme « MoveTo » qui utilisent du pathfinding, etc. Pour saisir un objet, c’est simple, on balance une animation et on grip l’objet au plus proche de la pince… c’est confortable. Mais en robotique, c’est loin d’être aussi simple ! le robot n’a pas un « level » qu’il peut interroger – enfin, pas directement. C’est la reconstruction du « niveau » par le robot qui nous intéresse.
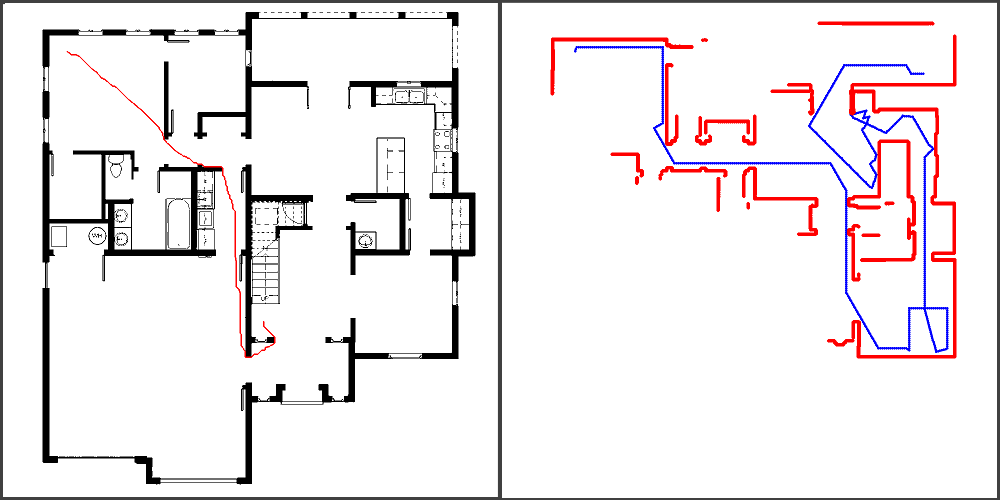
Je crois que l’une des premières tâches à laquelle il faut réfléchir, c’est la « compréhension » par le robot de son environnement. Cela commence par une capacité à cartographier les lieux et à détecter des « volumes ». Ensuite, reste à identifier ces volumes et reconnaitre des objets. C’est déjà une tâche assez complexe et nous allons rester sur la partie cartographie pour cet article. SLAM signifie Simultaneous Localization And Mapping: cela consiste à construire ou améliorer une carte de son environnement et de s’y localiser.
Le robot doit, pour cela, collecter un certain nombre de données de son environnement et utiliser ses propres bases de données, de règles et de faits, pour prendre des décisions en fonction de la tâche qui lui est assignée.
Pour collecter des données, le robot utilise des capteurs: cela va du capteur ultrason, à la balise GPS, en passant par les caméras et capteurs lasers. Nous allons prendre un exemple simple, connu de tous: le kinect de Microsoft. C’est loin d’être le meilleur, mais ça nous donne une base d’étude.

Le Kinect est une caméra dite « RGBD » : c’est à dire qu’au delà du pixel (RGB), elle fournit également une indication de distance pour chaque point. Nous aurions pu également utiliser plusieurs caméras, avec des angles différents, pour déduire la distance. C’est ce que font nos yeux !
Les caractéristiques à retenir sont celles-ci:
- Lentilles détectant la couleur et la profondeur: en fait, c’est le couple caméra IR/Laser qui sert à l’estimation de distance.
- Champ de vision horizontal : 57 degrés – Champ de vision vertical : 43 degrés – Capteur motorisé pour suivre les déplacements (Marge de déplacement du capteur : ± 27 degrés)
- 640 × 480 en couleur 32 bits à 30 images par seconde – Bon, ça pêche un peu de coté là…
- caméra IR en pus de RGB, mais ne dépasse pas quelques mètres
La précision de la Kinect est relativement bonne pour de faibles distances mais qu’au-delà de quelques mètres elle devient trop importante pour être exploité correctement. Cela reste surtout fonctionnel pour de l’intérieur. Mais passons, peu importe le capteur, intéressons nous à la méthode.
La THEORIE
Dans tous les cas, nous utilisons la techniques des points d’intérêt. C’est un point qui caractérise de façon unique une partie de l’image. Nous en avons déjà parlé avec l‘article sur ACAZE. l existe une multitude d’autres méthodes de détection/description de points d’intérêt parmi lesquelles SIFT et SURF. Il s’agit de méthodes particulièrement appréciées pour leur robustesse et leur efficacité.
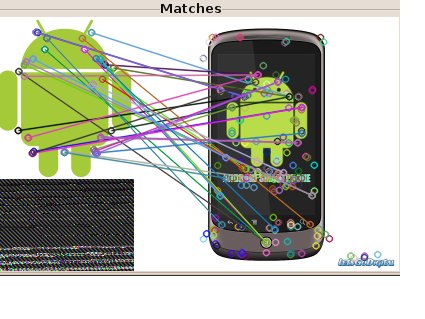 Une fois les points d’intérêts calculés dans chaque image il faut pouvoir déterminer quel est le mouvement global de la caméra. Pour cela on doit trouver quelle transformation permet de recoller correctement les deux nuages de points formés par les points d’intérêt.
Une fois les points d’intérêts calculés dans chaque image il faut pouvoir déterminer quel est le mouvement global de la caméra. Pour cela on doit trouver quelle transformation permet de recoller correctement les deux nuages de points formés par les points d’intérêt.
L’algorithme RANSAC (RANdom SAmple Consensus) est classiquement utilisé pour extraire un modèle d’un ensemble de données bruitées. L’estimation de mouvement avec RANSAC est en générale assez bonne mais dans le cadre de la construction d’une carte il est préférable d’affiner cette estimation avec une autre méthode comme ICP. ICP (Iterative Closest Point) est un algorithme qui permet de minimiser la distance entre deux nuages de points A et B.
Avec ces méthodes combinées on peut donc estimer le déplacement de la caméra entre deux images successives. On reconstruit alors au fur et à mesure des déplacements la trajectoire de la caméra tout en modélisant l’espace 3D.

Bien que la précision de ces méthodes soit bonne, on constate une dérive de la position au cours du temps due à l’accumulation des erreurs de mesure. L’algo SLAM permet de corriger les erreurs accumulées pendant la phase d’estimation de mouvement en vue d’obtenir un modèle cohérent de l’environnement.
En fait, on part du principe que ni la position de départ ni l’estimation du mouvement du robot ne sont exactes. On va donc insérer un peu de probabilités dans l’algo. Il existe deux formes de SLAM. Le premier nommé «online problem» consiste à calculer à chaque instant la position actuelle du robot en fonction des estimations de mouvements et des observations. La seconde est nommée «full SLAM problem» et consiste cette fois à calculer à chaque instant l’ensemble de la trajectoire à partir de l’odométrie et des observations. Donc dans le premier cas, la position, dans le second, la trajectoire complète.
La PRATIQUE
Bon, je ne vais pas entrer dans le détail dans le fond de l’algorithme, mais voyons plutôt comment l’utiliser. Nous allons utiliser le projet RTAB-Map: La détection de fermeture de boucle est le processus impliqué en SLAM lorsqu’on tente de trouver une correspondance entre un endroit présent et un autre déjà visité. Plus la carte interne augmente en taille, plus le temps requis pour la détection de fermeture de boucle augmente, ce qui peut affecter le traitement en temps réel. RTAB-Map est une nouvelle approche de détection de fermeture de boucle fonctionnant en temps réel pour du SLAM à grande échelle et à long terme.
Ce projet s’appuie sur d’autres librairies:
- TORO: c’est l’implémentation de l’algo principal de SLAM
- ROS: Pour la visualisation – ROS est un méta système d’exploitation open-source qui fournit l’ensemble des services classiquement fournis par un système d’exploitation comme la gestion des tâches de bas niveau ou les communications inter-process. Il fournit aussi un très grand nombre d’outils et de bibliothèques facilitant les développements.
- PCL (incluse dans ROS): Il s’agit d’une bibliothèque dédiée au traitement de données type nuage de points (Point Cloud Library). Ca fonctionne sous windows, Linux, MacOs, Android et iOS – c’est parfait. PCL supporte Kinect mais aussi d’autres periphériques et standards. Et ce qui ne gâche rien, il y a des bindings pour Python (nativement en C++). Et puis ça nous changera d’OpenCV qu’on connait déjà bien.
- Openni (incluse dans ROS): pour la récup des données de la Kinect.
Pour ma part, j’ai commandé l’adaptateur Kinect 360 pour PC et je compte enchainer les tests autour de RTAB-Map pour voir ce qu’il a dans le ventre. J’aimerais aussi coupler l’ensemble à un autre système de capteurs pour les environnements extérieurs, mais on verra un peu plus tard. Donc, soyez patient, la suite d’ici quelques mois après mes premiers tests.



0 commentaires